Web Sitelerinden Veri Çekme İşlemi HtmlAgilityPack
Bu konumuzda bir site içerisindeki html bloklardan nasıl veri çekebileceğiniz konusunda bilgi vereceğim.

Htmlagilitypack şu şekilde çalışır öncelikle bir web sitesinin url’i bulunur ve o url string halde html’e dönüştürülür ve daha sonrasında o url içerisinden html bloklarındaki Xpath alanları bulunarak o alanlar htmlnode olarak gelir ve o nodeların içerisindeki innertext’den değişkeni alıp veriyi çekip kullanmış olursunuz
ilk olarak Nuged Package’den HtmlAgilityPack’i yüklüyoruz

Kodu anlatacak olursak ilk olarak mainurl’de site adresini yazıyoruz daha sonra bir webclient oluşturup o url’e request atıp gelen html’i HtmlDocument şeklinde tutuyoruz
string mainUrl = "https://stackoverflow.com/";
HtmlDocument doc = new HtmlDocument();
WebClient client = new WebClient();
client.Encoding = Encoding.UTF8;
client.Headers.Add("user-agent", Guid.NewGuid().ToString());
string downloadString = client.DownloadString(mainUrl);
doc.LoadHtml(downloadString);
Daha sonra sitedeki çekilecek yer belirleniyor ben kategorileri çekmeyi göstereceğim.
![]()
şimdi sıra geldi nav bölümünü bulmaya chrome veya herhangi bir inspector’u (ögeleri denetle) olan browser’ınızı açıyorsunuz ve daha sonra tam o satırı seçip inspect’e basıyorsunuz ve otomatik o html bölüm açılıyor

Daha sonra html kod’a sağ tıklayak Copy=> Copy xPath’e basıyoruz daha sonra kodumuza geri dönüyoruz

Elimize aşağıdaki gibi bir kod geldi şimdi bunu noteslar arasını arayıp text’i bulalım
/html/body/header/div/ol[1]/li[1]/a
Gördüğünüz gibi xpath geldi bir değişkene attık ve about yazısını alabidik
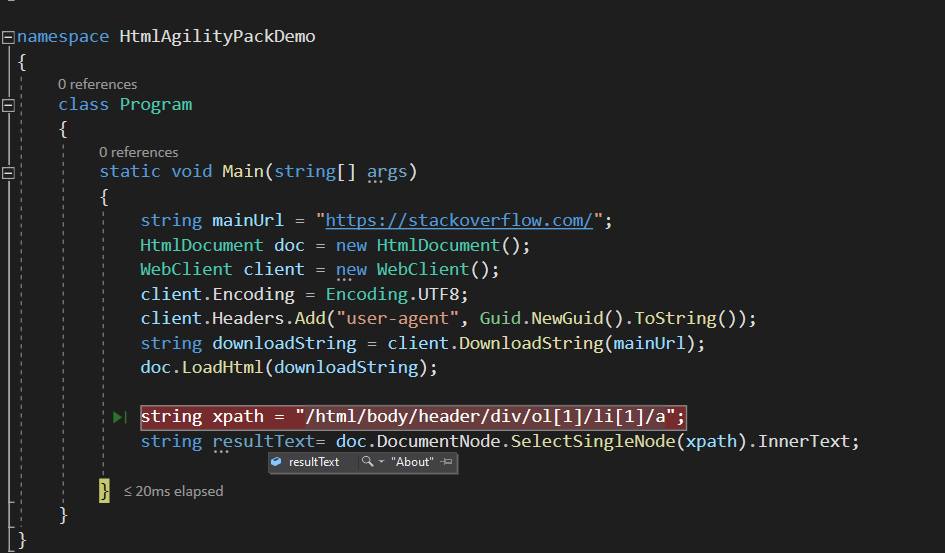
Eğer birden fazla alan çekmek isterseniz For ile dönüp bir bir artırıp diğer bölümleri de çekebilirsiniz gayet başarılı bir sonuç oldu.

Örnek Projeyi Github’dan Görmek İçin Tıklayabilirsiniz.












